|
A fuzzy logic C++ library
|
|
A fuzzy logic C++ library
|
NAVIGATION
This page describes how you can automatically build a rule base from training data.
You need to have an idea on the range of your data, because you have to first set up input and output sets of membership functions. This can be done using the application data-analysis.cpp.
For now, lets assume you know min and max values, and that you have a FIS correctly defined (the easiest way is to generate the sets of functions automatically from these min-max values). All you have to do is define the granularity of your set (the number of functions used). (For more on defining sets of functions, see page Sets of membership functions.)
One you have set up inputs and output of the Fis, learning the rules from data can be done in two ways:
This means adding a new rule at the time you get a data point, so you don't need to store all the datapoints. It implies more steps, as you need to:
First, adding rules. This can be done this way:
int NbInputs = 4; // for example std::vector<REALVAL> in_val(NbInputs); // a vector of 4 values while( NotFinished ) { // get input data in vector 'in_val' .... // get corresponding output data in out_val REALVAL out_val = ... // Create a rule from these values fis.AddRuleFromValues ( in_val, out_val ) }
This will create a new rule for each data vector. Each rule will be assigned a fuzzy "degree" value (can be fetched with RULE_IDX::GetDegree() ), whose value defines how much a data point fits to the rule it produced. The degree is computed as the product of the different membership functions values.
For example, say we have a FIS with three inputs {A,B,C}. For a given input value 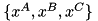 , we first search the membership
, we first search the membership 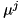 functions that "triggers" the value with the maximum fuzzy value
functions that "triggers" the value with the maximum fuzzy value  . The degree of the corresponding rule will be computed as
. The degree of the corresponding rule will be computed as 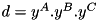 .
.
In real life, the data can be fetched directly from some other piece of software, but it can also be stored in a file. This library provides code for reading data files in several formats, see Dataset handling.
Before using the FIS, you need to reduce the rule base, as there will be both redundancy and contradictory rules. This is be done with a call to SLIFIS::ReduceRuleBase().
Several methods are available for reducing the number of rules. They all are based on the "Wang & Wendel" technique (see References). We group all equal rules together in several tables, one for each output, and then select the group of rules that gives one output, and reduce it to a single rule.
At present, three methods are available (See slifis::EN_REDUCE_METHOD for details):
For the third method, the degree of the winner rule is kept as is. For the first two methods, the degree of the final rule is computed as the ratio of the sum of all the degrees of the considered group of rules over the number of rules (i.e. it is the mean value of the degrees of the considered subset of rules).
This is done with SLIFIS::FactorizeRuleBase().
This aims at reducing the number of rules by grouping rules that are similar into a single rule. For example, consider a 3-input FIS where:
Say we have the following rule base:
r1: IF input1 is 'blue' AND input2 is 'high' and input3 is 'high' THEN output is 'great' r2: IF input1 is 'blue' AND input2 is 'high' and input3 is 'medium' THEN output is 'great' r3: IF input1 is 'blue' AND input2 is 'high' and input3 is 'low' THEN output is 'great' r4: IF input1 is 'red' AND input2 is 'low' and input3 is 'medium' THEN output is 'good' r5: IF input1 is 'green' AND input2 is 'low' and input3 is 'low' THEN output is 'bad'
The three first rules can be factorized to a single rule, thus giving:
r1: IF input1 is 'blue' AND input2 is 'high' THEN output is 'great' r4: IF input1 is 'green' AND input2 is 'low' and input3 is 'medium' THEN output is 'good' r5: IF input1 is 'green' AND input2 is 'low' and input3 is 'low' THEN output is 'bad'
This can be done only because:
Factorisation is not always possible, particularly when the number of rules is too small, or when the inputs have many membership functions.
Once you have filled a DATA_SET object, the whole process described above can be done at once:
SLIFIS fis;
// ... define inputs/output
DATA_SET dataset;
// ... load it with values
RBB_PARAMS params; // parameters for rule base building
fis.BuildRuleBaseFromData( dataset, params );
You can adjust the parameters by editing values in RBB_PARAMS (default values are provided).
For a Mamdani Fis type, it basically does the same as above (add rules one by one, then reduce, then factorize, depending on the selected parameters in RBB_PARAMS). For a TS Fis type, it produces a rule from each data point and computes the corresponding coefficients. In that case, no reducing neither factorisation is done (outputs coefficients are computed using an estimation process, it is very unlikely that they are the same from one rule to another...)
For a TS Fis, you need to have all the data available in a single DATA_SET object before building the rules. (see Dataset handling). Then, just as for a Mamdani Fis, call the SLIFIS::BuildRuleBaseFromData() function (see above). This will call SLIFIS::BuildTSRulesFromValues() and will compute a rule for each possible combination of inputs (assuming there are enough data points to cover all the possible situations). For example for a 3-input Fis with 3 MF for input 1, 4 MF for input 2 and 2 MF for input 3, then this will produce 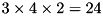 rules.
rules.
The process does the following steps:
For each rule, the fitting is done with the extracted subset of data, building the following linear system, and solving it. For example, for a FIS with 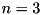 inputs, say we have
inputs, say we have 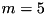 data points in the considered subset.
data points in the considered subset.
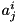 is the value for input i, for data point n° j,
is the value for input i, for data point n° j,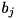 is the output value for data point n° j,
is the output value for data point n° j, is the TS coeff for input i (what we are looking for).
is the TS coeff for input i (what we are looking for).We need to build the following 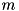 equations:
equations:
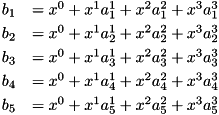
This can be expressed using matrix notations:
![\[ [\mathbf{A}]. [\mathbf{x}] = [\mathbf{b}] \]](form_44.png)
with:
![$ [\mathbf{x}] $](form_45.png) a vector of
a vector of 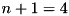 elements (3 inputs plus the constant term)
elements (3 inputs plus the constant term)  ,
,![$ [\mathbf{b}] $](form_48.png) a vector of elements (as much as the data points) holding the output values:
a vector of elements (as much as the data points) holding the output values:  ,
,![$ [\mathbf{A}] $](form_50.png) a matrix ( lines x
a matrix ( lines x 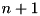 cols ) holding all the input values :
cols ) holding all the input values :\f{matrix}{
1 & a^1_1 & a^2_1 & a^3_1 \\
1 & a^1_2 & a^2_2 & a^3_2 \\
1 & a^1_3 & a^2_3 & a^3_3 \\
1 & a^1_4 & a^2_4 & a^3_4 \\
1 & a^1_5 & a^2_5 & a^3_5
\f}
The numerical value for can be computed by: ![$ [\mathbf{x}] = [\mathbf{A}]^{-1} [\mathbf{b}] $](form_52.png) but it is well-known that this is numerically unstable, so we proceed with an SVD solving instead.
but it is well-known that this is numerically unstable, so we proceed with an SVD solving instead.
For Eigen usage, see http://eigen.tuxfamily.org/dox/TutorialLinearAlgebra.html
 1.7.6.1
1.7.6.1